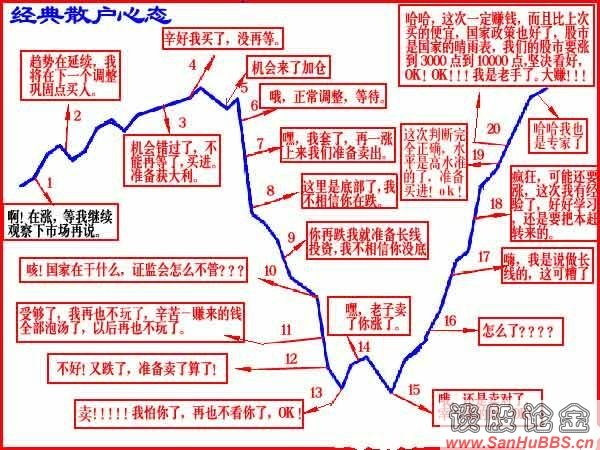
不转不行,太有意思:
来自:http://blog.csdn.net/nnnnyyyy/archive/2011/05/10/6410554.aspx
最欣赏的是这个:
以下是原文:
偶是一个程序员。
偶的生活很简单.确切地,用两个词,来说,就像偶写的代码一样,单调且无聊。
早上七点被手机叫醒:

睁开眼,刷牙,洗脸,吃早饭
八点半到办公室是必须的,然后开始一天工作:

那什么时候下班昵?偶不知道是会是几点钟:

从日出到日落,从星期一到星期天,日子就像是写错了代码产生的一个死循环:

每周双休?对偶来说只能是一种奢望:

平时,他们都叫偶:X工。其实只有偶最清楚,X工不是说偶是一个姓X的工程师,而是一个姓X的
民工:

偶没有钱,

偶也没有MM,

有的只是改不完的虫虫(Bug)和发不完的版本,

2007年比以往时候来的更早一些的第一场雪下过之后,偶买了股票和彩票
但是最终发现还是回家做豆腐的好;

但是残酷的现实总是令人无奈的,穿偶的眼神你完全可以发现"无奈"这个字并不是那样的空洞 :

偶真的是:叔可忍,婶也不能忍(出处:赵本山小品。原文:是可忍孰不可忍):

面对这样的生活,偶要大声吼一声:

遥想当年偶是一个:

曾经是那样的意气风发:

在夜深人静的时候,偶弹起心爱的土琵琶,唱起那动人的歌谣(柯受良-《大哥》):
偶写了代码好多年,
偶不爱冰冷的床沿,
不要逼偶想念,
不要逼偶流泪,
偶会翻脸
偶问自己:难道偶的人生只能是一个杯具么?

不是,不是这样的.
偶坚信
MM,会有的

面包也会有的

爱情... ... 也会有的
不要问为什么,就因为偶们是一个程序员。偶们勤劳、善良,上天会眷顾偶们的。
看到这篇帖子的和没有看到这篇帖子的都请大声地祝福偶们吧
阅读全文....
阅读全文....
第二次使用别人的引擎碰到用OpenGL线性过滤算法放大图片出现黑边的问题了,而引擎的制作者竟然不知道怎么解决,两次碰到此问题时都是试图教导我使用最近点过滤方式绕行,我很无奈,帮助其解决一下,顺便将问题简单的记录于此。
OpenGL在放大图片时有两种方法,一种是最近点(NEAREST),一种是线性(LINEAR),虽然在OpenGL里面,设置纹理参数的时候都称为过滤(filter),都通过glTexParameteri函数设置。比如二维时,设置线性过滤:
glTexParameteri( GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR );
放大时实际算法为插值(
interpolation)。
具体的
最近点过滤算法参考
,
线性过滤算法参考
。
简单的讲,最近点过滤算法就是用最靠近像素中心的那个纹理单元进行放大和缩小,效率更高,效果不好,锯齿严重。
线性过滤算法是对靠近像素中心的2*2纹理单元(二维时,三维为2*2*2),取加权平均值,用于放大和缩小。效果更好,效率稍低。(参看《OpenGL编程指南》第六版)
一般来说,我们常用Linear方式,但是Linear方式有个问题,那就是碰到边缘时怎么处理的问题,一种是取边缘外元素作为普通点进行加权计算,一种是不取。
为了方便演示,我使用一张Android SDK中附带的图片,并放大2.0f倍,多次紧密排列绘制,以观察效果,主要绘制源代码如下:
void DrawImage(float x, float y, float scale) {
glBegin(GL_QUADS);
glTexCoord2f(0.0 , 0.0 ); glVertex3f(x, y, 0.0f);
glTexCoord2f(1.0 , 0.0 ); glVertex3f(x + (gImg.Width * scale), y, 0.0f);
glTexCoord2f(1.0 , 1.0 ); glVertex3f(x + (gImg.Width * scale), y + (gImg.Height * scale), 0.0f);
glTexCoord2f(0.0 , 1.0 ); glVertex3f(x, y + (gImg.Height * scale), 0.0f);
glEnd();
}
void DrawImages(float x, float y) {
DrawImage(x, y, 2.0f);
DrawImage(x + gImg.Width * 2.0f, y, 2.0f);
DrawImage(x, y + gImg.Height * 2.0f, 2.0f);
DrawImage(x + gImg.Width * 2.0f, y + gImg.Height * 2.0f, 2.0f);
}
当然,这里我主要关心linear方式,所以:
glTexParameteri( GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER,
GL_LINEAR );
glTexParameteri( GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER,
GL_LINEAR );
在默认时,OpenGL
是默认设置GL_REPEAT的
,此时,加权的纹理单元是从原纹理单元的相反一侧去取。效果的好坏依赖与图片的内容。
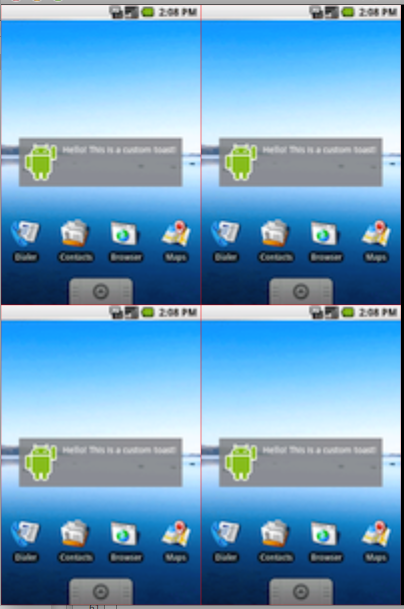
绘制4张图片时感觉效果还行:
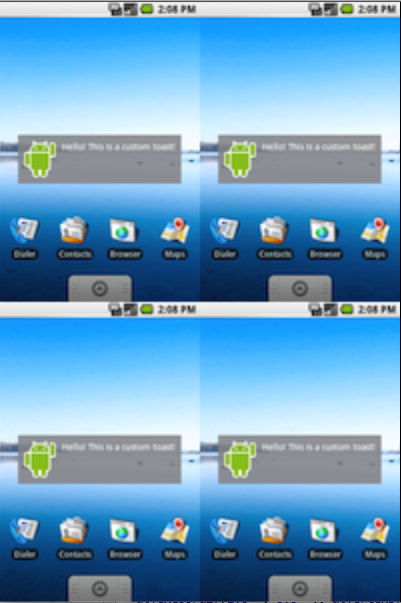
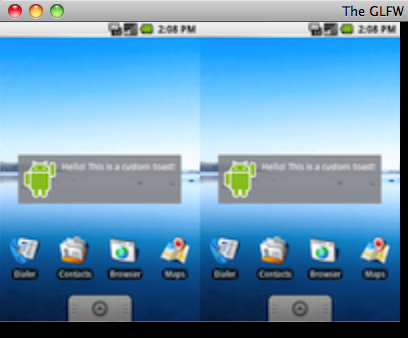
但是仅绘制上面两张图片时,效果明显有问题,可以看到下面有明显的白边(加权计算来自于上面白色的状态栏)
在OpenGL中,还有几种情况
1.GL_CLAMP,线性算法会取边框外的像素点进行计算,导致黑边,这也就是常见的黑边效果。
2.
GL_CLAMP_TO_EDGE,忽略边框,为简单设置时想要的正确效果。
3.GL_CLAMP_TO_BORDER,添加边框颜色值,在纹理坐标超出边框时,按设定的颜色值进行计算,在没有为边框设置值时,效果类似GL_CLAMP。(可以将此时的边框值看做为黑色)
比如,我用如下方法,设置一个红色边框值,
glTexParameteri( GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_BORDER);
glTexParameteri( GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_BORDER);
float color[4] = { 1.0f, 0.0f, 0.0f, 1.0f };
glTexParameterfv( GL_TEXTURE_2D, GL_TEXTURE_BORDER_COLOR, color);
效果就会如下,明显多出一个红色边框:
加入还觉得不够明显的话,修改draw函数,
void DrawImage(float x, float y, float scale) {
glBegin(GL_QUADS);
glTexCoord2f(-0.1 , -0.1 ); glVertex3f(x, y, 0.0f);
glTexCoord2f(1.1 , -0.1 ); glVertex3f(x + (gImg.Width * scale), y, 0.0f);
glTexCoord2f(1.1 , 1.1 ); glVertex3f(x + (gImg.Width * scale), y + (gImg.Height * scale), 0.0f);
glTexCoord2f(-0.1 , 1.1 ); glVertex3f(x, y + (gImg.Height * scale), 0.0f);
glEnd();
}
这下意思明显了吧:
以上是OpenGL的情况,OpenGL ES的情况又需要单独讲一下:
OpenGL ES 1.1中,只有两种情况,REPEAT(默认),和
GL_CLAMP_TO_EDGE。
参考这里
。
Android的情况,在我手机(Nexus S)中,默认的Repeat方式,会看到黑边。(这个有点奇怪,与OpenGL中的现象不一样)设置为
GL_CLAMP_TO_EDGE后,问题解决。
iphone上的情况,望知情人通知,目前没有时间测试。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
初创公司,没有像大公司那样的技术积累,很多东西需要自己从头干起,其中较大的一块就是工具。想起刚刚参加工作半年的那会儿,老板为了说服我写工具,说让我进工具组是培养我,写了一个数据校验工具后,我就死活再也不肯开发工具了,硬要继续写服务端程序。现在真是轮回,这次我是发现,我们实在是太需要工具了,于是决定自己写工具来提高公司的游戏开发效率。
于是,首先用本周时间,开发了一个用于编辑游戏layout的工具,使用的UI库是Qt。这个虽然是在公司有在MacOS下使用工具的需求下做出的选择,但是还是不得不说,对比3年前学习和使用MFC的经历,总体来说是心情愉快了很多。
Qt的学习断断续续,虽然我的博客中有个Qt的分类,但是在之前其实了解的还是比较浅的,除了大概翻看过《C++ GUI Qt 4编程》(第二版)一书,用Qt结合OpenGL做了一些小的动画demo,基本没有开发过啥实际的东西。说起来这还是第一次在工作中使用到Qt,中间多少还是走了一些弯路,也碰到过一些问题,这里大概总结一下,想到哪就说到哪了。
使用Qt的时候,还走了一些弯路,一部分也算是自己了解Qt不深入,一部分应该也算是Qt的设计问题。
Model的自定义使用:
insertRows,removeRows需要自己实现,大部分时候仅仅需要:
beginInsertRows(parent, row + 1, row + count);
endInsertRows();
return true;
和
beginRemoveRows(parent, row , row + count - 1);
endRemoveRows();
return true;
但是还是需要自己实现,不然的话实现是空的,那么是没有删除和添加效果的。相当不理解,那rowCount是干啥用的?其实应该只需要update/refresh一下就好了。或者,emit一下Qt中已经有的rowsInserted或者rowsRemoved signal也就好了,但是在rowsInserted,rowsRemoved信号的文档中明确的表示这两个消息不允许子类调用的,“It can only be emitted by the QAbstractItemModel implementation, and cannot be explicitly emitted in subclass code.”
而insertRow和removeRow是调用insertRows和removeRows来实现的,(文档如此描述)所以我们不需要实现了。不知道哪种逻辑更为正确,插入多行是多次插入呢,(所以插入多行可以通过多次调用插入一行实现)还是插入一行是插入多行的特殊情况呢?(就如同Qt这样反过来实现)
beginMoveRows和endMoveRows系列就更有意思了,因为没有moveRows用于重载..............那么,这些protected的函数什么时候调用呢?
最后找到了layoutChanged信号,发现只需要在改动后emit此信号即可刷新。并且insert和remove都可以实现。原来........Qt设计者眼中的update/refresh名字叫做layoutChanged.........相当晕。
使用QAction作为快捷键的时候,在一个列表空间中创建,发现无论如何都无法出发triggered信号,最后只能在全应用程序的菜单中添加action了事........这个比较困惑,也就是说没有局部快捷键?
对Qt的了解有限,使用一周,为了防止同一个坑掉进去两次,特写下一些东西作为回头查阅的资料,觉得不对的请提出来。
阅读全文....
本文不会涉及到你该使用UDP还是TCP,是FTP还是HTTP,也就是跟P都没有关系。^^ 同时,也不涉及该使用私有协议还是标准协议,还是在标准协议下使用私有协议, 而是会谈及在具体的协议编写的时候,使用哪种编写的方式会更好。由于本人的知识有限,谈及利弊时,主要以使用C++编写服务端时的经验为主,至于同时适不适用于其他语言,就靠童鞋们自己分辨了。
第一层境界:新手入门
因为我一开始工作的第一家公司就是精于服务端程序编写的公司(运营过百万级同时在线以上),所以实际上我以前都不太清楚真有公司处于此水平,直到真的碰到时,我才惊慌失措,感叹不已。
特点:信手拈来,直观质朴
也就是写一个结构,在任何需要使用的时候(典型环境就是打包解包,读写文件)一个变量一个变量的通过memcpy等方式处理。简单是简单,没有任何抽象。
但是,
1.非常的不符合
DRY原则,在此情况下,服务器端的打包解包代码和客户端的打包解包代码都得两份。别说服务器只需要打包,客户端只需要解包,这是太理想的情况,太经常一个小结构会需要传来传去的。而无论这个结构用多少次,你都得多为其写一次代码。
2.扩展性差:任何底层协议的改动,你都得更改除了相关数据结构意外的地方,(这也算是不符合DRY原则带来的副作用)而且此更改你往往得通过搜索才能完成。甚至,同一个数据结构即使仅仅是打包解包都做不到
DRY原则。需要进行版本控制时,相关代码也会散布在各打包解包各处,更何况,当你想要以其他方式(比如写入文件)保存此数据结构的时候,你又得重新来一次,简直就是不人道的。
3.容易出错:在上层打包解包代码,都需要关注于每个结构的每个字段的数据类型,任何一个类型错误,你能够预期到的最好结果就是crash。
第二层境界:序列化
通过序列化的概念,通过函数抽象实现同一个数据结构打包解包的DRY。通过函数重载,减少不同类型的不同处理。
特点:统一接口,各司其职
面向对象有的时候会代码对象层次过多等乱七八糟的问题,但是此处面向对象的使用,我感觉实在是太淋漓尽致的体现将面向对象的好处了。我记得以前有个关于对象设计的原则,那就是告诉对象要做什么,而不是去获取数据自己来做。在第一层境界中的做法就完全是自己获取结构中的数据,外部来完成工作,为什么不更面向对象一点,让这种工作由对象本身来完成呢?此时,因为序列化的本质是从接口到二进制之间的转换,对于网络打包解包,文件读写可以做到通过传入不同参数用同样的接口来完成,对于每个类/结构的数据只需要进行一次的编码,极大的减少了错误的发生概率。 能达到这个境界的工作已经算是比较有技术的公司了。
但是,
1.对于服务器客户端语言不同时的情况,再次的无法实现DRY,典型的应用就是以JAVA写服务器,而以C++写游戏时。
2.版本控制还是太过于手动化。
第三层境界: 代码生成代码
《Unix编程艺术》中描述的至高境界....代码生成代码,元编程的本质。第一次领悟这种境界是通过Google Protobuf,后来还知道一个thrift。
特点:描述结构,自动生成
以Google Protobuf为例,在写一个网络协议的时候,你不是直接的用一种语言编写协议,而是用特定的描述语言来描述这个协议的内容,然后通过工具自动的生成你需要的特定语言的结构。这样的好处是一次的描述,可以自动的为你生成多个语言的协议文件。(DRY,Protobuf官方支持C++,JAVA,Python,第三方支持的更多)更重要的是,这个接口的打包解包接口已经也生成好了,直接调用即可。当然,这个方法也不是完美的,简单的说,你需要学习怎么描述这个协议,你需要用工具生成代码,简单的说就是比直接写增加了复杂性。
小结:
其实还有其他的协议编写方式,比如用XML,Json的纯文本协议,这个也是一种较佳的方式,调试非常方便,只是效率上比起二进制的还有差距,而在第三层境界中,为了调试方便,为生成的结构增加一个日志输出接口,也能较为方便的调试。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
新浪微博 -- 腾讯微博 -- 讨论新闻组 -- 代码库 -- 豆瓣
新浪微博应该算是近期最火爆的了,虽然算是中国社交网络中较新的成员,但是却最具有王者的霸气。目前已经完全凌驾于传统社交网络人人网和开心网之上了,(甚至有数据显示此两者在萎缩了)这点对比国外的facebook和twitter,不禁感叹一下中国的特色国情。
大概看了一下文档,整个API是基于http的XML和Json文本协议,不知道是发扬光大于facebook还是twitter开放平台,这种方式极大的提高了API的可用性,简化了客户端方面对API的使用方式。这也是《Unix编程艺术》一书中,Raymond评价很高的一种互联网协议设计。
很欣喜的是,新浪微博光是objc的SDK就给出了两个:
一个是官方的:http://code.google.com/p/weibo4objc/
一个是由网友@宝玉xp提供的:http://code.google.com/p/sinaweiboios/
最后发现事实没有想象的那么好,官方的那个感觉代码写的很稚嫩,API设计的感觉虽然简单,但是不足够好,可能作者并不是专业的objc开发者,就新浪的实际情况来看。。。。会不会是做微博的PHP开发者-_-!虽然作为SDK使用者,不应该这样说,毕竟吃果子不忘栽树人嘛,呵呵,但是还是自以为较为客观的描述一下,大家看看代码和API就知道了。
而网友提供的那个,根本就不是SDK,而是从TwitterFon客户端改造过来的一个应用程序,虽然感觉代码的成熟程度比前面的官方的SDK强太多了。
那么还是用真的SDK吧。注册帐号,添加新应用。
再checkout了代码,更改帐户和密码和添加新应用时sina给的custom key,测试了一下demo.....发现报错,“limited application access api!”然后一查,(
见这里)吓一跳,原来中国的开放平台就是这样的,碰巧被我碰到无通知的升级。哈哈,不是当机了就说升级吧。(谁开发过服务端程序谁知道^^)使用无果。
说到API设计不足够好,(代码就不说了,自己看吧)看一个最常用的例子:
Status * statusme = [weibo statusUpdate:@"api Test" inReplyToStatusId:nilReplyId latitude:nilLatitude longitude:nilLongitude];
weibo是Weibo类。我明明就想发一个纯文字的信息,结果需要拖这么长的一个尾巴。。。。。甚至还有带inReplyToStatusId的这种,为啥我发信息需要调用一个API来表示不是回复消息呢?完全可以,也实在应该再封装一层。statusUpdate: (NSString)就可以了。
而最让人意外的是其实是有下面这样一个带图片的新消息的接口的:
[weibo statusUpload:@"111" pic:@"pic_path" latitude:nilLatitude longitude:nilLongitude];
其实我刚开始以为这个API才是发布新消息的时候用的,但是我不需要图片的时候,尝试以下两种方式调用:
[weibo statusUpload:@"111" pic:nil latitude:nilLatitude longitude:nilLongitude];
[weibo statusUpload:@"111" pic:@"" latitude:nilLatitude longitude:nilLongitude];
结果都是会报错的。(本地的错误)这样的抽象,这样的接口,其实还是有点让人意外+无语的。
腾讯微博虽然发布的晚,(策略失误所致)但是因为其庞大的平台效应,发力后还是不容小觑。因为开发的晚,所以目前开放平台也没有sina那么好,前1,2个月,我看其开放的SDK时,甚至都还没有iphone平台下可用的SDK。但是好在现在有了。
稍微浏览了一下代码和API,发现腾讯iOS SDK中的代码比新浪的要干净漂亮很多,呵呵,可能开发的人要专业一些(虽然以前出过抄袭事件,但是感觉开发者还是要专业一些)不过专业是专业了,API设计的也实在是太专业了:
QWeiboRequest *request = [[QWeiboRequest alloc] init];
NSURLConnection *connection = [request asyncRequestWithUrl:url httpMethod:@"POST" oauthKey:oauthKey parameters:parameters files:files delegate:aDelegate];
类似的API从表面上是做到了一条API干净简洁的通过参数(上面的parameters)完成所有任务,而且还有增加新功能不用添加API的优点。(仅添加参数即可)但是实际上将所有用户拉入只能先看文档后写代码的境地,也许设计API的人应该先看看《
设计Qt风格的API》,了解一些API设计的基本原理吧。API是设计给人用的,而不是想着自己怎么设计简单来设计的。对于这种API,我个人是觉得比新浪的那种还要糟糕。
稍微了解了怎么使用后,尝试添加应用,我一下就蒙了,需要填写包括手机号码,身份证号码,地址,公司等一大堆的东西,怎么搞的像审查罪犯?
再结合这个
权限的设置,真是受不了啊。有人来做开发者,对平台是有好处,最后好像是开发者求你?我联想到最近的“
You Win, Rim”的事件,套用其原话,此时此刻,千言万语汇成一句话:你赢了,腾讯。做开放平台难道是来给开发人员添堵的吗?姿态开放而心态不开放的开放很明显是假的开放。最后的效果也很明显,目前新浪微博平台上的应用很繁荣,而腾讯微博平台的应用几乎没有,这可不全都是因为慢了一步而已。
小结:,,
假如不允许批评,那么所有的赞美都没有意义。我较为苛刻,对两个微博的SDK都提出了一些看法。我的感觉,新浪需要的是加强技术,腾讯需要的是改变心态。但是无论是新浪还是腾讯,只要能够真的拥抱开放,我想不仅是两个公司的平台能够做的越大越强,同时也能给个人和小团队提供新的机会,让大家在中国这片神奇的国土上,也能做点符合自己理想的事情,同时,获得一定的收益,那样,也算是中国互联网在不停的倒退的时候的一点进步吧。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
新浪微博 -- 腾讯微博 -- 讨论新闻组 -- 代码库 -- 豆瓣
程序员最大的问题在于对美术的依赖。 -- 工作以来的最大感慨
看过老罗的海淀剧院演讲后,大家都应该知道该怎么办了......................
新公司对产品的设计和交互(可以浓缩为用户体验4字)有近乎苛刻的要求,受其文化影响,最近超出程序员的范围,看了一些关于设计和交互的书籍,收获不少。由于以前一直使用腾讯微博,博客中很多人留言告诉我新浪微博更好,要我使用新浪的,因为腾讯微博中很多朋友在也没有多在意。直到前段时间碰到一个朋友,一句"在我认识的人里面,使用腾讯微博的人还真是不多",虽然说的很委婉,但是很明显的,我被严重的鄙视了。。。。。。于是乎,今天下午,开始尝试使用新浪微博,因此,在我的博客发布模板中,添加了右上角的
新浪微博的链接。
但是,说新浪微博好的人很多很多,但是真的很好吗?好在哪里?以我的不专业的眼光,"体验了"(公司专用术语)一下新浪的微博,感觉产品做的其实有一些不足,导致,我的新浪微博几乎已经变成了我对新浪微博的抱怨专博,唉,我甚至愿意在这里总结一下,有疑议的,尽管大家提出来讨论。
新浪微博的iphone客户端体验和弄不好,就不多举例子了,在我抱怨其不好以后,大部分朋友推荐我使用第三方开发的weico客户端。但是即使都是eico这个国内著名的设计公司设计的,我感觉都不是很好,就算不说设计上的问题,bug也的确比较多,特别是刷新上的问题。这一点,ipad的新浪微博也同样有。
讲网页微博的设计吧,新浪是做网站出身的:(其实一下内容都是来自于我在新浪微博上发的抱怨的微博,所以可能有些过于口语化,见谅)
1.从页面风格的色彩搭配来说,新浪微博背景的颜色有些过淡(惨淡,惨淡的)右边框与背景颜色区分度太小,同时搜索的时候,因为右变宽也变白了,页面过白,因为这个改变,同时也导致搜索与平时的页面页面的风格不统一的问题。虽然设计在不同人的眼里会有不同的意见,但是我感觉大部分人会同意这一条。
2.网页刷新内容过慢,刷新几分钟,提示的新粉丝都还是看不到,这种情况,可以列入bug,的确应该改进。
3.关注一个细节,左边腾讯微博的页面用的是标签页的展示方式,而右边新浪微博是按钮,哪个更好自有公论,不过,在看过《Don't make me think》后,我倾向与标签页的方式,因为表达的含义更多。

4.名人堂,只有每个分类的关注已选,没有一个统一的关注已选,使用不是太方便?
更多的就不谈了,稍微总结一下吧:
新浪微博的优势自然是很明显的,起步早,又有其天生的媒体基因的优势,合理的借鉴了从新浪博客学来的名人效应。
但是,说到具体的产品,今天正好看同事在微博上谈到新浪的微博,他的意思也是新浪就是做内容的媒体公司,血液里面就没有做产品的基因。我是非常的同意啊,也许,这也解释了,为啥新浪的iphone微博客户端做的不是很好,同时,几大门户在网游行业赚的盆满钵盈的时候,新浪却一小块蛋糕都没有分到。怎么做优秀的产品,新浪尚需学习。也许这个问题,不是后面童鞋评论中说的没钱的问题,新浪很缺钱吗?我感觉是公司重点关注的东西在哪的问题。当然,我不是新浪的人,具体怎么样,也就只有公司内部的人才能知道了。
最后:
看一看几大门户的微博页面吧,几乎一模一样,(现在很多产品都这样)感叹现在创意和产品都被模仿的很严重,最后并不一定就是新来者会取得胜利,而是最关注产品的用户体验,最关注产品的每个细节的公司取得最后胜利。新浪的确有领先的优势,但是假如以此以为可以高枕无忧,那就错的太远了,路途尚远,新浪+U。
PS:原文因为来自刚开始使用新浪微博时在新浪微博上的抱怨,言辞有些过于激烈,被一些人认为是软文,在此表示抱歉,今天将一些较“过”的语言删除掉,使得文章更为公正一些。
阅读全文....
前一篇在这里。
Lisp特性列表
表处理(List Processing):
Lisp:
CL-USER> (defvar *nums* (list 0 1 2 3 4 5 6 7 8 9 10))
*NUMS*
CL-USER> (list (fourth *nums*) (nth 8 *nums*) (butlast *nums*))
(3 8 (0 1 2 3 4 5 6 7 8 9))
CL-USER> (remove-if-not #'evenp *nums*)
(0 2 4 6 8 10)
在Lisp中几乎什么都是list。。。。比在lua中什么都是table还要过分,因为不仅是数据,任何表达式,函数调用啥的也是表。。。。。不过用惯了[n]形式的我,还是对first,last,rest,butlast,nth n这种获取表中特定索引值的方式有些不适应。但是很明显有一点,Lisp对list的操作是不用循环就支持遍历的,看起来也许你会说不过就是语法糖而已,其实代表了更高层次的抽象,这就象C++中STL的for_each,transform一样,只是,他们的使用有多么不方便,我想每个用C++的人都能体会。
Python中虽然不是什么都是列表,但是Python对于list的处理还算是比较强大。
Python:
>>> l = list(range(11))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> lo = [l[3], l[7], [l[0:len(l)-1 ]]]
>>> lo
[3, 7, [[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]]
>>> [x for x in l if not x % 2]
[0, 2, 4, 6, 8, 10]
lisp comprehensions(列表解析)这个强大的特性的存在,可以使得Python做类似Lisp的这种不使用外部循环的遍历与Lisp一样的方便。(特别提及,列表解析是用从与Lisp同族的函数语言Haskell学过来的)
其实,这里我想多说几句,能够直接(即不使用循环)来对一个序列进行操作是非常方便的,也是更高级的抽象,这样才符合我们应该表达Do what,而不是去表达How to do,而用循环就是表达How to do的低层次了。事实上,即使在C++中,我们也是更喜欢高级抽象的,这也完全不会有性能损失,比如前面提到的for_each,transform,其实还有min_element,max_element,都是典型的例子,但是,对比Lisp和Python,还是显得功能比较弱小。
Lisp:
CL-USER> (defvar *capital-cities* '((NZ . Wellington)
(AU . Canberra)
(CA . Ottawa)))
*CAPITAL-CITIES*
CL-USER> (cdr (assoc 'CA *capital-cities*))
OTTAWA
CL-USER> (mapcar #'car *capital-cities*)
(NZ AU CA)
关联列表,类似C++中的map,Python中的字典,我并没有感觉有多么强大。。。。。
Python:
>>> capital_cities = { "NZ" : "Wellington", "AU" : "Canberra", "CA" : "Ottawa"}
>>> capital_cities["CA"]
'Ottawa'
>>> [ x for x in capital_cities]
['NZ', 'AU', 'CA']
在Python中,遍历一个dict默认是遍历key,所以用列表解析可以很简单的处理。虽然,Python在这些方面完全不输于Lisp,但是得提到,Python之所以不输给Lisp...是因为它从Haskell学到了列表解析.......
匿名列表(Lambda lists):
CL-USER> (defun explode (string &optional (delimiter #/Space))
(let ((pos (position delimiter string)))
(if (null pos)
(list string)
(cons (subseq string 0 pos)
(explode (subseq string (1+ pos))
delimiter)))))
CL-USER> (explode "foo, bar, baz" #/,)
("foo" " bar" " baz")
CL-USER> (explode "foo, bar, baz")
("foo," "bar," "baz")
Lambda一般童鞋都不会太陌生,说的通俗点叫匿名函数,稍微现代点的语言都有,我以前还尝试过C++的Boost::Lambda
,但是这个特性不是指lambda,因为太普通了,看清楚了,是lambda list, 不过说的虽然玄乎,其实还是比较普通,相当于参数传递的时候是利用了list的特性,可以实现可选参数以及关键字参数而已(也叫Named arguments),默认参数也许对于C还算神奇,可选参数对于C++都很普通了,关键字参数是BS主动放弃的C++特性之一,(见《C++设计与演化》在Python中完全支持。有点意思的是,上面的例子用了递归来实现string的遍历。。。。实在是太花哨了。。。。。而这个例子对于Python来说实在太普通了,Python甚至自带此函数实现的功能,我都懒得实现了。。。。。。
Python:
>>> import string
>>> "foo, bar, baz".split(",")
['foo', ' bar', ' baz']
>>> "foo, bar, baz".split()
['foo,', 'bar,', 'baz']
第一类值符号:(First-class symbols)
Lisp:
CL-USER> (defvar *foo* 5)
*FOO*
CL-USER> (symbol-value '*foo*)
5
听多了第一类值函数,倒是很少听说第一类值符号,在Lisp中,符号可以作为变量的名字,也可以就是作为一个占位符,说白了就有点像不当字符串处理的字符串。Python中应该没有类似概念。。。。。上文说多了Python没有类似的东西的话,惹得一些Python粉丝怒了,这里对我浅薄的Python知识表示抱歉,谨以此娱乐,作为了解Lisp特性的一种消遣,不要太当真,语言真的算不上啥信仰,平台也不是啥信仰,神马都是浮云,用着开心就好。
第一类值包:(First-class packages)
CL-USER> (in-package :foo)
#<Package "FOO">
FOO> (package-name *package*)
"FOO"
FOO> (intern "ARBITRARY"
(make-package :foo2 :use '(:cl)))
FOO2::ARBITRARY
NIL
没有看懂有什么太强的作用,注意上面的代码在使用:foo包后的反应....命令行提示符都变了,同时也明白了,以前的CL-USER其实就是代表CL-USER包,在Lisp中包也就是类似命名空间的作用,虽然说C++的命名空间真的也就是个空间,但是JAVA,Python,Lua中的包已经非常好用了,不仅带命名空间,而且带独立分割的实体。此条不懂,不知道是Lisp的古老特性在现在太流行了,所以变得已经没有什么好奇怪的了,还是说,我太火星了?高手请指教。
特别的变量:(Special variables)
Lisp:
FOO> (with-open-file (file-stream #p "somefile"
:direction :output)
(let ((*standard-output* file-stream))
(print "This prints to the file, not stdout."))
(print "And this prints to stdout, not the file."))
"And this prints to stdout, not the file."
"And this prints to stdout, not the file."
话说Lisp的变量是动态语法范围的,也就是说你可以将变量的范围动态的从全局变为局部,反之亦然,这个有点反常规。但是就例子中的代码看,就像是重定向功能,是将标准输出定向到某个文件上,这个功能Python也有。
Python:
>>> import sys
>>> stdoutTemp = sys.stdout
>>> sys.stdout = open("somefile", "w+")
>>> print("This prints to the file from Python, not stdout.")
>>> sys.stdout.close()
控制转移:(Control transfer)
翻译过来有些不好懂,大概的意思就是执行语句从一个地方跳到另一个地方,类似从汇编时代就有的goto语句。
Lisp:
CL-USER> (block early
(loop :for x :from 1 :to 5 :collect x :into xs
:finally (return-from early xs)))
(1 2 3 4 5)
CL-USER> (block early
(loop :repeat 5 :do
(loop :for x :from 1 :to 5 :collect x :into xs
:finally (return-from early xs))))
(1 2 3 4 5)
可能有些不好懂,其实此时的return-from就类似于goto,而block就像是C++的以:开头的标识。
Lisp:
CL-USER> (defun throw-range (a b)
(loop :for x :from a :to b :collect x :into xs
:finally (throw :early xs)))
THROW-RANGE
CL-USER> (catch :early
(loop :repeat 5 :do
(throw-range 1 10)))
(1 2 3 4 5 6 7 8 9 10)
Catch/throw语法的跳转,有点像现代语言的异常了,事实也是如此,看看例子中的cath吧,对:early throw出一个xs值,然后后来每次都能catch住,这个有点意思,虽然有点诡异。。。。。。
也许是因为现代的语言已经足够的强大了,即使是从命令式语言繁衍过来,(命令式语言的本质是模拟和简化机器语言)也慢慢的具有了越来越高级的抽象,并且也学习了很多函数语言的东西,所以,其实,语言的选择并没有那么重要,(参考这里)根据具体的情况进行选择,什么熟悉,什么用的高兴就行。(当然,不是一个人高兴,是整个开发团队)
另外,这里还看到一本特别有意思的书《Python for Lisp Programmers》,其中较为详细的列举了Python和Lisp的相同及不同,可以看到Python其实与Lisp还是比较像的,其中也有一些关于现在语言的效率信息,可以作为参考,也算给看了上一篇文章并且对Lisp比Python快有疑义的人的一种回答。其实这个世界的人都很怪,用C/C++的人可以强调效率,因为我们高效嘛,用Python的人可以强调我们类伪码,开发效率高嘛,现在程序员的时间比机器的时间要贵重的多,于是C/C++的人又回答了,你用Python给我开发个操作系统试试,Python本身都是C语言编写的,类似的争吵不在少数。呵呵,但是,当效率和抽象都要更加强大的时候,那就更加有话语权了,就如Lisp的使用者宣称Lisp是世界上最好的语言一样.........其实~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~

最后,感觉后来的Lisp特性就没有前面的那么特异和突出了,有些平淡,再加上晚餐喝了几两二锅头,所以现在也不多写了,待续吧。。。。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
BS,Gosling,Anders,Guido都要被打屁股?
以前就听说过Lisp被很多人认为是世界上最好的语言,但是它是那么的古老,这种言论很可能来自于不能进化到学习Ruby,Python的老古董,所以其实也没有太在意。
Lisp(这里特指Common lisp,下同)1978年被设计完成,是个多么古老的语言啊。。。。却总是不停的听到太多的Lisp的好话,总是感觉有些难以相信,BS说,"一个新设计的语言不比老的好,那新语言的设计者是要被打屁股的",假如Lisp还是世界上最好的语言,那么从BS自己,到James Gosling到Anders到Guido van Rossum 不都要被打屁股啊?
你说我能轻易相信吗?
“如果我们把流行的编程语言,以这样的顺序排列:Java、Perl、Python、Ruby。你会发现,排在越后面的语言,越像Lisp。”这个话真的可信吗?
正好碰到一篇妄图说服我的文章《Features of Common Lisp》,眼见为实,是骡子是马,跑起来看看^^本文以Features一文为线索,(标题翻译的不好,请童鞋们见谅)与Python作为对比,C++啥的就都不太好意思拿出来比了,因为总是可以以效率为理由搪塞过去,但是,有可能我还是顺带提及一下。但是,总的来说,这是在Lisp的领地上战斗,,C++,Python是很吃亏的,但是作为已经足够强大的语言,还能够自我革新,Python的最新版本(3.1.1,以下没有特指,均指此版本)能够怎么应付,我拭目以待。特别提及,相比Lisp实现,CPython的运行速度慢得惊人,甚至差5-10倍,对于一个牺牲速度来换取表达性的语言,要是比不过速度比自己快那么多的语言,实在有些说不过去,即使是在别人的地盘..........迎战的Lisp是lispbox-0.7版本中集成的common lisp。
Lisp特性列表
强大抽象的数学计算(Rich, exact arithmetic):
大数(Bignums):
不用当心溢出。
Lisp:
CL-USER>
(expt (expt (expt (expt 10 10) 10) 10) 10)
100000000000000000000000000000000000...
这个貌似还行,C++虽然是需要通过外部库来处理,(在新标准中有过关于大数的提案,我以前还翻译过一篇《(N1744)Big Integer Library Proposal for C++0x
》)
但是Python对大数的支持还是非常不错的,特别提及,在Python2.1时代,虽然有大数支持,但是你得自己指定,假如都是用普通整数,还是会溢出。在2.2以后版本中已默认会进行类型提升。(参考PEP237
)呵呵,这点挺符合越新的语言(在Python来看,也就是越新的版本越接近)也就是越接近Lisp的理论。
Python:
>>> ((((10 ** 10) ** 10) ** 10) ** 10)
1000000000000000000000000000000000000000000
.....
分数(Rational numbers):
保留成比例的形式。
Lisp:
CL-USER>
(+ 5/9 3/4)
47/36
这个很牛很牛。。。。我目前懂的语言,(C/C++,Lua,Python,Objc以后提及均表示此意)还没有哪个是这样计算分数的,给你的都是浮点数。
特别提及一点,在Python2.x时代,上面的整数运算会像C++中那样,直接变成整数(5/9也就是0),但是新版本中已经不那么扭曲了。
Python 2.6.4:
>>> 5 / 9
0
Python3:
>>> 5 / 9
0.5555555555555556
我很遗憾的表示,同样的,python3比2.X版本更加像lisp,但是还不是足够像。
复数(Complex numbers):
内建支持
Lisp:
CL-USER>
(* 2 (+ #c(10 5) 4))
#C(28 10)
这个也还算方便,虽然我平时好像也用不上,C++中得通过库处理。Python也内建支持。
Python:
>>> (((10 + 5j) + 4) * 2)
(28+10j)
相对来说,以近似伪码著称的Python表达还是更加清晰一些。
统一的引用(Generalized references):
Lisp:
CL-USER> (defvar *colours* (list 'red 'green 'blue))
*COLOURS*
CL-USER> (setf (first *colours*) 'yellow)
YELLOW
CL-USER> *colours*
(YELLOW GREEN BLUE)
CL-USER> (push 'red (rest *colours*))
(RED GREEN BLUE)
CL-USER> *colours*
(YELLOW RED GREEN BLUE)
Lisp的操作都是使用引用对列表进行操作,你可以改变这个列表,实际操作的是同一个列表,就像你使用了rest操作,并对其进行push,但是实际也还是会改变原来的colours,因为rest返回的也还是引用而不是临时变量,这个特性看起来很有意思,有些特殊,具体的使用范围我还不是太清除(因为毕竟没有lisp编写大型的程序)
比如:
Python:
>>> l
['red', 'yellow', 'green', 'blue']
>>> l ;
['red', 'yellow', 'green', 'blue']
>>> l = ["red", "green", "blue"]
>>> l[0] = "yellow"
>>> l
['yellow', 'green', 'blue']
>>> l[1:]
['green', 'blue']
>>> l2 = l[1:].insert(0, "red")
>>> l2
>>> l
['yellow', 'green', 'blue']
需要注意的是,l[1:].insert(0, "red")操作是不会返回['red','green','blue']的,这样你临时的变量都获取不到,同样的,用切片操作来模拟的话,不仅没有返回值,原列表更不会改变,因为切片后的是临时变量,而不是引用。
多重值(Multiple values):
Lisp:
CL-USER> (floor pi)
3
0.14159265358979312D0
有简单的内建语法支持多个值,因此能方便的让函数返回多个值。此点C++就靠其他手段吧,比如异常ugly的用传指针/引用,然后再通过指针/引用传出去,虽然用了这么多年的C++了,这种方式也习惯了,但是一比较,就知道那不过是个因为语言的抽象能力太弱,使用的walk round的办法而已。 Python还是可以的。
虽然,Python的floor不返回两个值。
Python:
>>> import math
>>> math.floor(math.pi)
3
但是,你的确是可以返回多个值。
Python:
>>> def myFloor(x):
return math.floor(x), x - math.floor(x)
>>> myFloor(math.pi)
(3, 0.14159265358979312)
但是,需要特别注意的是,这只是个假象......因为实际上是相当于将返回值作为一个tuple返回了。
Lisp:
CL-USER> (+ (floor pi) 2)
5
在计算时,让第一个多重值的第一个变量作为计算的变量,所以非常方便。
因为Python的返回值如上面所言,其实是用tuple模拟多个返回值的,不要奢望了。
Python:
>>> myFloor(math.pi) + 1
Traceback (most recent call last):
File "<pyshell#58>", line 1, in <module>
myFloor(math.pi) + 1
TypeError: can only concatenate tuple (not "int") to tuple
不过,lua倒是可以,可能lua还是从lisp那吸收了很多东西吧:
Lua(5.1.2以下同):
> math.floor(math.pi)
> print(math.floor(math.pi))
3
> function myFloor(x)
>> return math.floor(x), x - math.floor(x)
>> end
> print(myFloor(math.pi)+ 1)
4
而且在Lisp中可以很方便的使用多重值的第二个值。(通过multiple-value-bind)
Lisp:
CL-USER> (multiple-value-bind (integral fractional)
(floor pi)
(+ integral fractional))
3.141592653589793D0
Python因为返回的是tuple,指定使用其他值倒是很方便,包括第一个(虽然不是默认使用第一个)
Python:
>>> myFloor(math.pi)
(3, 0.14159265358979312)
>>> myFloor(math.pi)[0] + myFloor(math.pi)[1]
3.141592653589793
最后,即使这样Lisp在表达方面还是有优势的,因为在lisp中floor只计算了一次,而python的表达方式得多次计算,除非起用临时变量。
宏(Macros):
lisp的宏有点像其他语言中的函数,但是却是在编译期展开(这就有点想inline的函数了),但是在Lisp的fans那里,这被称作非常非常牛的syntactic abstraction
(语法抽象),同时用于支持元编程,并且认为可以很方便的创造自己的领域语言。目前我不知道到底与C++的宏(其实也是一样的编译期展开),还有比普通函数的优势在哪。(原谅我才学Lisp没有几天)
LOOP宏(The LOOP macro):
Lisp:CL-USER> (defvar *list*
(loop :for x := (random 1000)
:repeat 5
:collect x))
*LIST*
CL-USER> *list*
(441 860 581 120 675)
这个我有些不明白,难道在Lisp的那个年代,语言都是循环这个概念的。。。。导致,循环都是一个很牛的特性?
继续往下看就牛了
Lisp:
CL-USER> (loop :for elt :in *list*
:when (oddp elt)
:maximizing elt)
675
when,max的类SQL寻找语法
Lisp:
CL-USER> (loop :for elt :in *list*
:collect (log elt) :into logs
:finally
(return (loop :for l :in logs
:if (> l 5.0) :collect l :into ms
:else :collect l :into ns
:finally (return (values ms ns)))))
(6.089045 6.7569323 6.364751 6.514713)
(4.787492)
遍历并且进行分类。
我突然想到最近Anders在一次关于语言演化的演讲中,讲到关于声明式编程与DSL
例子,用的是最新加入.Net平台的LINQ:
他表示,语言是从:
Dictionary<string, Grouping> groups = new Dictionary<string, Grouping>();
foreach(Product p in products)
{
if
(p.UnitPrice >= 20)
{
if
(!groups.ContainsKey(p.CategoryName))
{
Grouping r = new Grouping();
r.CategoryName = p.CategoryName;
r.ProductCount = 0;
groups[p.CategoryName] = r;
}
groups[p.CategoryName].ProductCount++;
}
}
List<Grouping> result = new List<Grouping>(groups.Values);
result.Sort(delegate(Grouping x, Grouping y)
{
return
x.ProductCount > y.ProductCount ? -1 :
x.ProductCount < y.ProductCount ? 1 : 0;
}
);
这种形式到:
LINQ:
var
result = products
.Where(p => p.UnitPrice >= 20)
.GroupBy(p => p.CategoryName)
.OrderByDescending(g => g.Count())
.Select(g => new
{ CategoryName = g.Key, ProductCount = g.Count() });
看看与Lisp有多像吧(连名字都像^^)。。。。。(具体例子参见《编程语言的发展趋势及未来方向(2):声明式编程与DSL》)
而,Anders提到这个是在2010年。。。。。Lisp是1958年的语言。。。这个恐怖了。。。
突然,《为什么Lisp语言如此先进?》里面的话,“编程语言现在的发展,不过刚刚赶上1958年Lisp语言的水平。当前最新潮的编程语言,只是实现了他在1958年的设想而已。
”在耳边响起。。。。。。因为Anders的例子更有意思,Python那简单的while,for循环,我就不列举了。
Format函数(The FORMAT function):
Lisp:
CL-USER> (defun format-names (list)
(format nil "~{~:(~a~)~#[.~; and ~:;, ~]~}" list))
FORMAT-NAMES
CL-USER> (format-names '(doc grumpy happy sleepy bashful sneezy dopey))
"Doc, Grumpy, Happy, Sleepy, Bashful, Sneezy and Dopey."
CL-USER> (format-names '(fry laurie))
"Fry and Laurie."
CL-USER> (format-names '(bluebeard))
"Bluebeard."
Format函数现在的语言基本都有,连C/C++语言都有,为啥值得一提?因为lisp的format更加强大。。。。。强大到可以自动遍历list(而lisp的最主要结构就是list)。上面的format可能感觉有些不好理解,其实主要是因为lisp中不用%而是用~,总体来说,不比C系语言的format更难理解,但是更加强大。最强大的地方就是~{~}组合带来的遍历功能。当然,最后一个单词带来的“and”,也是很震撼。。。这些都不是用一系列的循环加判断实现的,用的是一个format,强大到有点正则表达式的味道。
看python同样的例子,就能够理解了,要实现同样的功能,必须得加上外部的循环。
Python:
>>>import sys
>>>def format_name(list):
if len(list) > 0:
sys.stdout.write(list[0])
if len(list) > 1:
for index in range(1, len(list) - 1):
sys.stdout.write(", %s" % list[index])
sys.stdout.write(" and %s" % list[-1])
>>> format_name(l)
a, b and c
>>> format_name(l[0])
a
>>> format_name(l[0:2])
a and b
哪个更加简单,一目了然,lisp的format函数的确强大,即使在python3上也无法有可以媲美的东西。(新的format模版也好不到哪里去)
Functional functions:(不知道怎么翻译)
函数是第一类值,可以被动态创建,作为参数传入,可以被return,这些特性相当强大。这也算是函数类语言最强大的特点之一了。(也许不需要之一吧)记得
Lisp:
CL-USER> (sort (list 4 2 3 1) #'<)
(1 2 3 4)
回顾一下C/C++中的函数指针,C++中的函数对象有多么麻烦,看到这里差不多要吐血了。(PS:在新的标准中可能会添加进原Boost中的Function库,还是不错的,以前写过一篇关于这个
的,这同样也印证越现代的语言是向越来越像Lisp的方向进化,只是在C++中,表现为通过库来弥补语言本身的不足
)
Python,lua的函数都是第一类值,(这里有个讲Python的FP编程的文章,非常不错)所以用起来一样的方便,只是python原生的sorted倒是不支持类似的操作:
sorted
(iterable
[
, key
]
[
, reverse
]
)
不过我们可以自己实现。
Python:(改自这里的实现)
>>> def sort(L, f):
if not L:
return []
return sort([x for x in L[1:] if f(x , L[0])], f) + L[0:1] + /
sort([x for x in L[1:] if not f(x, L[0])], f)
>>> def less(a, b):
if a < b:
return True
else:
return False
>>> def greater(a, b):
if a > b:
return True
else:
return False
>>> l = [4, 2, 3, 1]
>>> sort(l, less)
[1, 2, 3, 4]
>>> sort(l, greater)
[4, 3, 2, 1]
总的来说,在这个函数编程的核心领域,Python还是不错的,看看上面的文章就知道,用Python也完全可以写出类似FP的代码,只是因为Python的OOP特性的存在,大部分人完全忽略了其FP特性而已。
《为什么Lisp语言如此先进?》里面举了个例子:
我们需要写一个函数,它能够生成累加器,即这个函数接受一个参数n,然后返回另一个函数,后者接受参数i,然后返回n增加(increment)了i后的值。
此时
Lisp:
CL-USER> (defun foo(n)
(lambda(i)(incf n i)))
FOO
Lisp的实现很简单,但是Python的如下实现:
Python:
def foo (n):
return lambda i: n + i
文中说这样的语法是不合法的。。。。。。。于是乎,作者猜想“Python总有一天是会支持这样的语法的”,而事实上,经我测试,现在的Python已经完全支持此语法。。。。。(修正以前文章中的错误,原来的测试有误,
这点也印证了程序语言进化的方向。)
但是,我还是感叹,即使学习了Python这样现代的语言,我的脑袋中也很少有关于函数的抽象,比如上面的例子中的那种,语言决定着你的思维的方式,决不是假话,我受了太多OO的教育,以至于失去了以其他方式思考程序的能力。
Joel Spolsky属于更为激进的一派,他认为,不良好支持函数抽象的语言根本不值的学习。(这里的函数抽象不是指有函数,而是指类似上面的形式。)现在的语言,从Ruby,Javascript,甚至Perl 5,都已经支持类似的函数编程语法,同时也感叹,能够进化的语言,你的学习总是不会白费的^^比如总是给我惊喜的Python。
未完,待续......................
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
凡客体以前确实火了一阵,但是都是恶搞,今天才看到这个看了深有同感,就像是在描述自己的,转过来,酷壳真是真的程序员哪.....
来自酷壳
.

不过,小孩子的C++ helloworld程序有问题...........也许在老的编译器上可以运行吧.........
阅读全文....

